Problem Name: All Possible Increasing Subsequences
LightOJ ID: 1085
Keywords: sorting, binary indexed tree
Continuing with my plan to write about data structures I have recently discovered, I’ll talk about a problem that can be solved with the help of a binary indexed tree. But we’ll get to that in a moment; let’s focus on the problem first.
In this problem we’re asked to consider sequences of integers. An increasing subsequence is simply an arbitrary subset of integers from the original sequence, kept in the same relative order, such that the numbers in the subsequence are in strictly ascending order. Putting it into more formal terms, let \(A\) be an array of \(N\) integers (indexed from zero to \(N-1\)). Then an increasing subsequence of length \(k\) can be described by a list of indices \(s_1, s_2, \ldots, s_k\) such that \(0 \leq s_1 < s_2 < \ldots < s_k < N\) and \(A[s_1] < A[s_2] < \ldots < A[s_k]\). Note that a subsequence can be of length one, which means that any number in \(A\) by itself forms an increasing subsequence.
The problem consists of finding the total number of increasing subsequences that can be found in a given sequence of integers. Let’s get our hands dirty with a simple example, which is always helpful to wrap our heads around problems and their solutions.
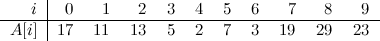
Here we have an array \(A\) of 10 elements, all distinct integers (pretty integers, by the way). At this point, you can try to find out the number of increasing subsequences in \(A\) by yourself, if you feel inclined to do so.
If you haven’t figured out a way to solve it yet, I recommend you give it a try, at least for a few minutes. It is important to spend the time doing that mental workout. Here’s a little hint, before I blurt out the strategy I have in mind: think about going step by step, in order.
Okay, here’s how the process might look like for this example. Hopefully it will help you get a grip on the core of the algorithm we’re going to use. We’ll take elements from the original sequence, one by one and in ascending order, and find out the number of increasing subsequences (ISS) we have found so far at each step:
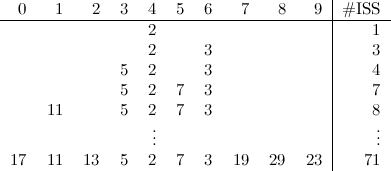
A few steps have been left out (try to complete the list), but did you get the gist of it? Let’s put it into words:
- Let \(S\) be an array of length \(N\), where \(S[i]\) will represent the number of increasing subsequences that end at position \(i\) (so the last number of those subsequences would be \(A[i]\)). Initially, all positions inside \(S\) will be set to zero.
- Consider tuples of the form \((A[i], i)\) for all \(0 \leq i < N\). Create all these tuples and sort them by their first element.
- Take each tuple \((A[i], i)\) in order, and perform the following calculation: \(S[i] = 1 + \sum_{j=0}^{i - 1}{S[j]}\)
With this, we have successfully calculated the number of ISS that end on each position of the array. The final answer is simply the sum of all elements from \(S\).
You might be thinking, all of this is very nice except for one small detail: the array \(A\) can be very large (its size can be up to \(10^5\)), and calculating all those sums make up for a complexity of \(O(N^2)\), which is prohibitively high!
That’s where our new data structure comes out to save the day. A binary indexed tree —also called a Fenwick tree— is a data structure that can store and update cumulative sums (prefix sums) in logarithmic time, as opposed to the traditional \(O(n)\) from a naive loop to accomplish the same task in an array. The way BITs work is fascinating, in case you want to delve into it a little more, but what’s important in the context of this problem is that by using a BIT, we can calculate all those sums in our algorithm very efficiently. So our problems disappear if we simply choose to implement \(S\) as a BIT (some adjustments are necessary, though, because BITs are not zero–indexed).
There is only one additional detail we haven’t considered yet. What happens if there are repeated numbers in \(A\)? Try it with pen and paper. Create a small array with some numbers occurring more than once. Now try to apply the algorithm described here. Can you identify the exact adjustment that needs to be done? Here’s a hint: it’s related to the sorting of the tuples. They need to be sorted by their first element first, but if there’s more than one tuple with the same first element, then the comparison needs to be done by their second element. But how? I’ll leave it as an exercise… Have fun :).
sorting isn't mandatory. I have an algorithm using binary indexed tree which can do the job without sorting. But good blog. Keep writing.
ReplyDeleteHey Pyshkar, can you share this algorithm please? I'm curios to see other approaches too.
DeleteAnd sorry for misspelling your name (fat finger).
DeleteThis comment has been removed by the author.
ReplyDeleteInsightful. Thank you
ReplyDelete