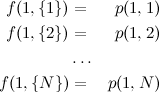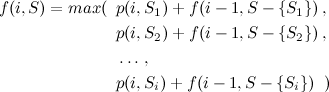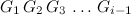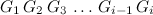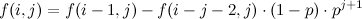Problem Name: A Dangerous Maze (II)
LightOJ ID: 1395
UVa ID: 12411
Keywords: probability, expected value
You are inside a maze, in front of a series of doors. By choosing a door, you follow a path, taking a certain amount of time, and at its end you find yourself either out of the maze, or back at the beginning. The question is, if the probability for choosing any given path is the same for all doors, then what is the expected amount of time to get out if the maze (if it’s at all possible)?
However, there’s an interesting twist: you also remember the last \(K\) decisions you made, and if you have previously chosen a door that takes you back to the beginning, you won’t select it again, as long as it remains one of your last \(K\) decisions.
I found the concept behind this problem very interesting, and at first I tried to come up with some sort of dynamic programming solution. However, after some consideration, it became clear that such an approach would be infeasible due to the problem constraints (the number of doors \(n\) can be 100, and \(K\) can be any number between 0 and \(n\)), and the intricate relations formed when you consider your K–sized memory.
So I tried the pure math way… armed with a pencil and a stack of paper, I filled many pages with equations and drawings to help me model the problem conveniently, making some mistakes along the way, correcting them, trying to find some kind of pattern until I could identify something that could let me formulate a conjecture that I could then translate into code. In this post I’ll try to summarise my findings.
First of all, let’s split the doors into two sets, and label them as follows:

Where \(a_i\) is the time for the ith door that takes you out of the maze, and \(b_i\) is the time for the ith door that leads you back to where you started. The total number of “positive” doors (the ones that lead you out) is denoted \(p\), and the total number of “negative” doors (the ones that take you back to the beginning) is \(q\). Notice that \(n=p+q\).
Now, let’s define \(E\) as follows:
- \(E(S)\)
- The expected amount of time to get out of the maze, after having visited the sequence of doors \(S\).
The sequence (ordered list) given as argument to the \(E\) function is important because it represents your “memory”.
When you’re just starting your journey, you haven’t visited any doors, so the value of \(E\) would look like this:
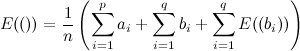
In other words, \(E\) is defined recursively, based on the fact that whenever you choose one of the \(b\) doors, you are back at the beginning, but having added your last decision to your sequence (note the use of parenthesis as notation for the sequences).
Let’s add a few more definitions, in order to simplify the expressions that come a little further below:

- \(\hat{E}_i\)
- The sum of all possible \(E(S)\), where \(S\) has exactly \(i\) elements.
With this, let’s reformulate \(E(())\), and see what happens when \(K=0\):

The equation [2] is the answer for the case where \(K=0\), meaning you can’t remember any previous decisions (which is, by the way, the same situation as in the first A Dangerous Maze problem, LightOJ ID 1027).
Things start to get interesting when you consider \(K > 0\):

Equation [3] requires the most attention, but it’s simply the result of thinking what is the result of adding \(E(\,(b_u)\,)\) for all possible values of \(b_u\).
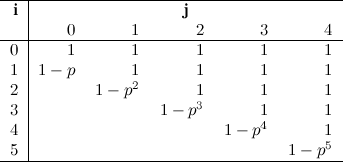
The same reasoning can be used for \(K=2\) and \(K=3\), but doing the actual calculations for \(\hat{E}_2\) and so on becomes increasingly difficult. You can try to deduce all of this for yourself, but suffice to say that the results for \(E\) with the first values of \(K\) are the following:

Can you see the pattern? (Also, do you see how I managed to fill pages upon pages with my conjectures and wrong turns?)
All in all, a very nice problem, with some interesting mathematics behind it. I still don’t know if there’s a shorter way to deduce the general formula (maybe using some number or probability theory I’m not aware of), instead of just using conjectures… If you have any ideas, let me know :).